LLM Implementations
ChatGPT and its competitors
Foundation Capital Ashu Garg and Jaya Gupta Beyond LLMs: Building Magic note that nearly 150 LLMs were released in 2023 alone, and predict three major future shifts for LLMs:
- Multimodal
- Agent
- New Model architectures including State Space (from Cartesia), Large Grahic Models (LGM) from Ikigai, RWKV (hybrid GPT/LLM that are more efficient at inference)
Good discussion, with many details and references.
Small Language Models
These are models with hundreds of millions or billions of parameters and tuned to work offline, including Microsoft researchers have developed and released two SLMs, namely Phi and Orca. French AI startup Mistral has released Mixtral-8x7B, which can run on a single computer (with plenty of RAM). Google has Gemini Nano, which can run on smartphones.
See Li et al. (2024)
TinyLlama is yet another new language model. TinyLlama is small: 1B parameters, but more than that, only requires 550 MB of memory to run. It was designed for small mobile and embedded devices.
You can try all the popular LLM Chatbots simultaneously with the GodMode smol AI Chat Browser.

OpenAI / ChatGPT
Amazon Olympus
This week, Amazon completed the second phase of a deal announced last September, when it committed to investing up to $4 billion in OpenAI rival Anthropic. The additional $2.75 billion invested is Amazon’s largest check ever into another company and yet another signal of how critical the development of large language models has become to Big Tech.
The training data for the secretive project is reportedly vast. The model will have a whopping 2 trillion parameters, which are the variables that determine the output of a given model, making it one of the largest currently in development. In comparison, OpenAI’s GPT-4 LLM has “just” one trillion parameters, according to Reuters.
Apple
Announced at WWDC June 2024: Apple’s On-Device and Server Foundation Models
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training “research paper sharing the architecture, training data and insights from building these. The largest model in MM1 is 30B and beats many 80B open-source LLMs in visual tasks.”
Also see Apple’s MLX (framework for running ML models on Apple silicon), Keyframer (an image animation tool)
rumors they might team up with Google Gemini.
paper (ReALM: Reference Resolution As Language Modeling), Apple describes an on-device model that takes into account both what’s on your screen and what tasks are active. Supposedly generates output as good as GPT-4.
Claude (Anthropic)
Anthropic @AnthropicAI
and Claude 3 which claims to beat other LLMs (see LLM Benchmarks)
The Claude 3 spec sheet with all the gory details of how the model was designed, including its various “safety” features.
also see Perplexity Copilot, which uses the Claude (and other?) API to give better answers.
Time Magazine wrote a brief summary of brother-sister founders Daniela and Dario Amodei
Cohere
Google (Gemini)
Getting Started with Gemini 1.5 Pro and Google AI Studio:
Why Google missed the boat on GPT-3 OpenAI engineer explains that Google’s internal TPU usage made it difficult to go all-in on the technology.
Known by the code-name Bard, Google’s Gemini 1.5 was announced in February 2024 and available to everyone for $20/month. It has a 1M token context window, which is enough to handle several books and more. By April 2024, it was already sustaining 25% the traffic of ChatGPT.
See Summary from Zvi
Technically, Gemini builds on Google’s world-class infrastructure and uses Ring Attention with Blockwise Transformers, to breaks long contexts into pieces to be computed individually even as the various devices computing those pieces simultaneously communicate to make sense of the context as a whole; in this case memory requirements scale linearly with context length, and can be extended by simply adding more devices to the ring topology.1
To use the larger context window, you’ll need AI Studio (I joined the waitlist)
Gemini Advanced is part of the Google One Premium Plan and costs $19/month. It includes 2TB of storage.
Google has built a new foundation model for time series. Like language models, and unlike most time series models, TimesFM is pretrained using time series data. It excels at zero-shot predictions.
Google has no moat is a supposedly-leaked internal Google memo that explains why open source versions of GPT language models will win. (via HN)
see counter-argument from Vu Ha
Is the 41% quality gap “slight”? IMO, it’s not. Our experiences have shown that a 50-to-60 improvement is significantly easier than a 80-to-90 improvement.
And a Jun 2024 argument from John Luttig that The future of foundation models is closed-source: if the centralizing forces of data and compute hold, open and closed-source AI cannot both dominate long-term
Yes, Google indexes dangerous information too, but the automation of LLMs is what makes it dangerous: a rogue model doesn’t simply explain a cyberattack concept like in a Google result, but instead can write the code, test it, and deploy it at scale – short-circuiting an otherwise arduous criminal activity.
Stanford’s NLP lab has only 64 GPUs, making it hard for academia to offer any real competition to the Big Tech arms race. ## Groq Not to be confused with the X “Grok”, this is a super-fast interference engine built on other LLMs, including Llama and Mixtral.
LLama (Meta)
Try the latest model for free on OctoAI
and also Inference.Cerebras.Ai which has a very fast response time.
What’s up with Llama 3? Arena data analysis gory details of LLama metrics.
It was trained on 2T tokens and they have models up to 70B parameters. The paper linked in the blog has rich details and impressive tidbits that the community has guessed at but never confirmed, primary of which is around the absolute foundational nature of training the reward model properly. It’s harder to get right than it seems.
Meta’s Llama model used 2,048 Nvidia A100 GPUs to train on 1.4 trillion tokens, a numerical representation of words, and took about 21 days, according to a CNBC report in March. (SCMP)
Nathan Lambert writes a Llama 2: an incredible open LLM on how Meta is continuing to deliver high-quality research artifacts and not backing down from pressure against open source.
While doubling the training corpus certainly helped, folks at Meta claim the reward model and RLHF process was key to getting a safe and useful model for Llama 2’s release. If you didn’t have time to read the full technical paper, this post is an excellent summary of key ideas from the head of RLHF at HuggingFace.
A blog post at Cursor.so makes the case for Why GPT-3.5 is (mostly) cheaper than Llama 2
Instructions for How to Run Llama-2 locally. The smallest model runs in 5-6G RAM and is 2-3GB of disk space.
Superfast AI Newsletter Alexandra Barr writes a detailed description of LLama: “Llama 2 Explained: Training, Performance and Results
Diving into Meta’s Llama 2 model and how it compares to SOTA open- and closed-source LLMs.”
Brian Kitano shows Llama from scratch (or how to implement a paper without crying): implements TinyShakespeare, essentially a chatbot trained on Shakespeare corpus using the same techniques as Llama did on its huge corpus.
Cameron Wolfe does a incredibly deep-dive
Microsoft
Phi 3 is a series of models, 3B-14B in size, which perform exceptionally well on modern benchmarks. The 3B model claims to outperform the original ChatGPT model. Weights have been released. There is a variant available with a 128k context length.
Abdin et al. (2024)
Bing Chat CoPilot
Dolma (AI2)
Dolma stands for “Data to feed OLMo’s Appetite”
AI2 Dolma: 3 Trillion Token Open Corpus for Language Model Pretraining

Our dataset is derived from 24 Common Crawl snapshots collected between 2020–05 to 2023–06. We use the CCNet pipeline to obtain the main content of each web page in plain text form. Further, we also use the C4 dataset, which is obtained from a Common Crawl snapshot collected in April 2019 ## X.AI (Grok)
Grok, released to Premium X users on Nov 5, 2023, has these goals
Gather feedback and ensure we are building AI tools that maximally benefit all of humanity. We believe that it is important to design AI tools that are useful to people of all backgrounds and political views. We also want empower our users with our AI tools, subject to the law. Our goal with Grok is to explore and demonstrate this approach in public.
Empower research and innovation: We want Grok to serve as a powerful research assistant for anyone, helping them to quickly access relevant information, process data, and come up with new ideas.
Grok-1 is currently designed with the following specifications:
- Parameters: 314B
- Architecture: Mixture of 8 Experts (MoE)
- Experts Utilization: 2 experts used per token
- Layers: 64
- Attention Heads: 48 for queries, 8 for keys/values
- Embedding Size: 6,144
- Tokenization: SentencePiece tokenizer with 131,072 tokens
- Additional Features:
- Rotary embeddings (RoPE)
- Supports activation sharding and 8-bit quantization
- Maximum Sequence Length (context): 8,192 tokens
trained a prototype LLM (Grok-0) with 33 billion parameters. This early model approaches LLaMA 2 (70B) capabilities on standard LM benchmarks but uses only half of its training resources. In the last two months, we have made significant improvements in reasoning and coding capabilities leading up to Grok-1, a state-of-the-art language model that is significantly more powerful, achieving 63.2% on the HumanEval coding task and 73% on MMLU.
March 2024: The initial model was released open source (see Github)
IBM (MoLM)
Open source Mixture of Experts “MoLM is a collection of ModuleFormer-based language models ranging in scale from 4 billion to 8 billion parameters.”
Now called Granite and still open sourced
These decoder-only models, trained on code from 116 programming languages, range from 3 to 34 billion parameters. They support many developer uses, from complex application modernization to on-device memory-constrained tasks.
IBM has already used these LLMs internally in IBM Watsonx Code Assistant (WCA) products, such as WCA for Ansible Lightspeed for IT Automation and WCA for IBM Z for modernizing COBOL applications. Not everyone can afford Watsonx, but now, anyone can work with the Granite LLMs using IBM and Red Hat’s InstructLab.
Mistral (France)
Jul 24, 2024 Mistral Large: - 128k context window - Trained on dozens of computer languages
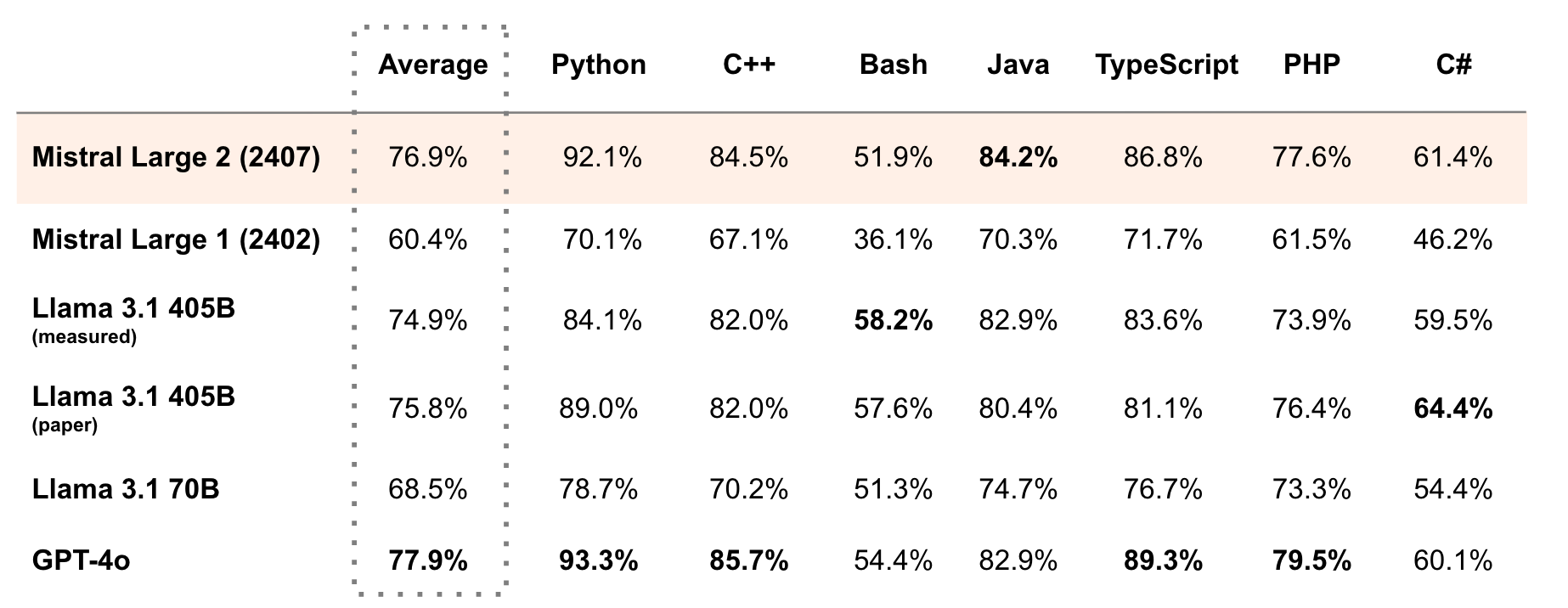
https://mistral.ai/ (via The Generalist) Founded by Guillaume Lample, Arthur Mensch, and Timothe Lacroix to build an ecosystem hinged on first-class open-source models. This ecosystem will be a launchpad for projects, teams, and eventually companies, quickening the pace of innovation and creative usage of LLMs.
Mistral-7B-v0.1 is a small, yet powerful model adaptable to many use-cases. Mistral 7B is better than Llama 2 13B on all benchmarks, has natural coding abilities, and 8k sequence length. It’s released under Apache 2.0 licence. We made it easy to deploy on any cloud, and of course on your gaming GPU
Try it out on HuggingFace Model Card for Mistral-7B-Instruct-v0.1
Perplexity
Attempting to become your premiere search destination, the company released its own AI large language models (LLMs) — pplx-7b-online and pplx-70b-online, named for their parameter sizes, 7 billion and 70 billion respectively. They are fine-tuned and augmented versions of the open source mistral-7b and llama2-70b models from Mistral and Meta.
see VentureBeat’s good summary.
Includes Yelp data

Reka
A Sunnyvale-based company co-founded by ex-DeepMind researcher Dani Yogatama and others.
Reka Core Multimodal Language Model

Chinese LLMs
01.AI: (China) (aka Yi)
An open source model from Kai Fu Lee’s company.
See Hacker News discussion
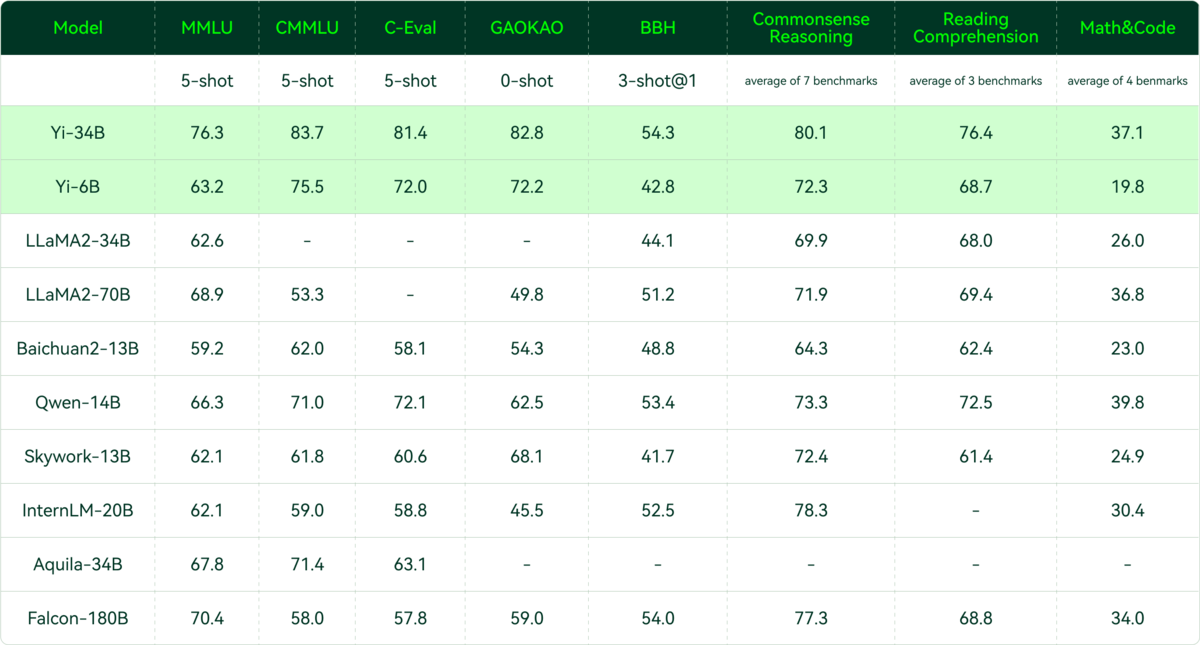
Tongyi Qianwen (Alibaba)
Tongyi Qianwen allows AI content generation in English and Chinese and has different model sizes, including seven billion parameters and above.
Alibaba will be open-sourcing the seven-billion-parameter model called Qwen-7B, and a version designed for conversational apps, called Qwen-7B-Chat
Open source Qwen-VL and Qwen-VL-Chat can understand images and carry out more complex conversations.
ERNIE (Baidu)
A professional plan that gives users access to Ernie Bot 4.0 for 59.9 yuan (US$8.18) per month
 文心一言
文心一言
有用、有趣、有温度
iFlytek (China)
Company says iFlytek Spark 3.0, first unveiled by the company in May, has outperformed GPT-3.5 in six abilities
Open Source
Varun: “Why Open Source will win”: lengthy, detailed argument why LLMs are like Linux and have a fundamental long-term advantage over closed source.
Open source models are smaller and run on your own dedicated instance, leading to lower end-to-end latencies. You can improve throughput by batching queries and using inference servers like vLLM.
There are many more tricks (see: speculative sampling, concurrent model execution, KV caching) that you can apply to improve on the axes of latency and throughput. The latency you see on the OpenAI endpoint is the best you can do with closed models, rendering it useless for many latency-sensitive products and too costly for large consumer products.
On top of all this, you can also fine-tune or train your own LoRAs on top of open source models with maximal control. Frameworks like Axolotl and TRL have made this process simple5. While closed source model providers also have their own fine-tuning endpoints, you wouldn’t get the same level of control or visibility than if you did it yourself.
Technology Innovation Institute and startups MosaicML and Together are pushing forward their own open-source AI software.
Allen Institute has released OLMo, an open source language model. There are 7B and 1B parameter versions, and it claims performance better than similarly sized models. OLMo is the first completely open model: every step in development and every artifact generated is available.
Japan LLMs
Microsoft will invest almost $3B for Generative AI Accelerator Challenge (GENIAC), a program led by the Ministry of Economy, Trade and Industry which helps innovative startups and established enterprises develop foundation models as a core technology of generative AI in Japan.
- Large Language Model (EvoLLM-JP)
- Vision-Language Model (EvoVLM-JP)
- Image Generation Model (EvoSDXL-JP)
We are excited to release 2 state-of-the-art Japanese foundation models, EvoLLM-JP and EvoVLM-JP, on Hugging Face and GitHub (with EvoSDXL-JP coming up), with the aim of effectively accelerating the development of nature-inspired AI in Japan!
Other
DarkBERT: A Language Model for the Dark Side of the Internet: a language model pretrained on Dark Web data, shows promise in its applicability on future research in the Dark Web domain and in the cyber threat industry.
Jin et al. (2023)
Eagle 7B is another new large language model. It claims to out-perform all 7B-class models while requiring the least computation power for inference. It is available on HuggingFace. While Eagle appears to be transformer-based, it claims to point the way “beyond transformers.”